Notes on Challenges and Applications of Large Language Models
This is a summary of an important research paper that provides a 93:1 time savings. It was crafted by humans working with several AI's. The goal is to save time and curate good ideas.
Search for a command to run...
This is a summary of an important research paper that provides a 93:1 time savings. It was crafted by humans working with several AI's. The goal is to save time and curate good ideas.
No comments yet. Be the first to comment.
This is a summary of an important research paper that provides a 22:1 time savings. It was crafted by humans working with several AI's. The goal is to save time and curate good ideas.

This is a summary of an important research paper that provides a 17:1 time savings. It was crafted by humans working with several AI's. The goal is to save time and curate good ideas.

This is a summary of an important research paper that provides a 22:1 time savings. It was crafted by humans working with several AI's. The goal is to save time and curate good ideas.

This is a summary of an important research paper that provides a 19:1 time savings. It was crafted by humans working with several AI's. The goal is to save time and curate good ideas.

This is a summary of an important research paper that provides a 17:1 time savings. It was crafted by humans working with several AI's. The goal is to save time and curate good ideas.

Link to paper: https://arxiv.org/abs/2307.10169
Paper published on: 2023-07-19
Paper's authors: Jean Kaddour, Joshua Harris, Maximilian Mozes, Herbie Bradley, Roberta Raileanu, Robert McHardy
GPT3 API Cost: $0.24
GPT4 API Cost: $0.20
Total Cost To Write This: $0.44
Time Savings: 93:1
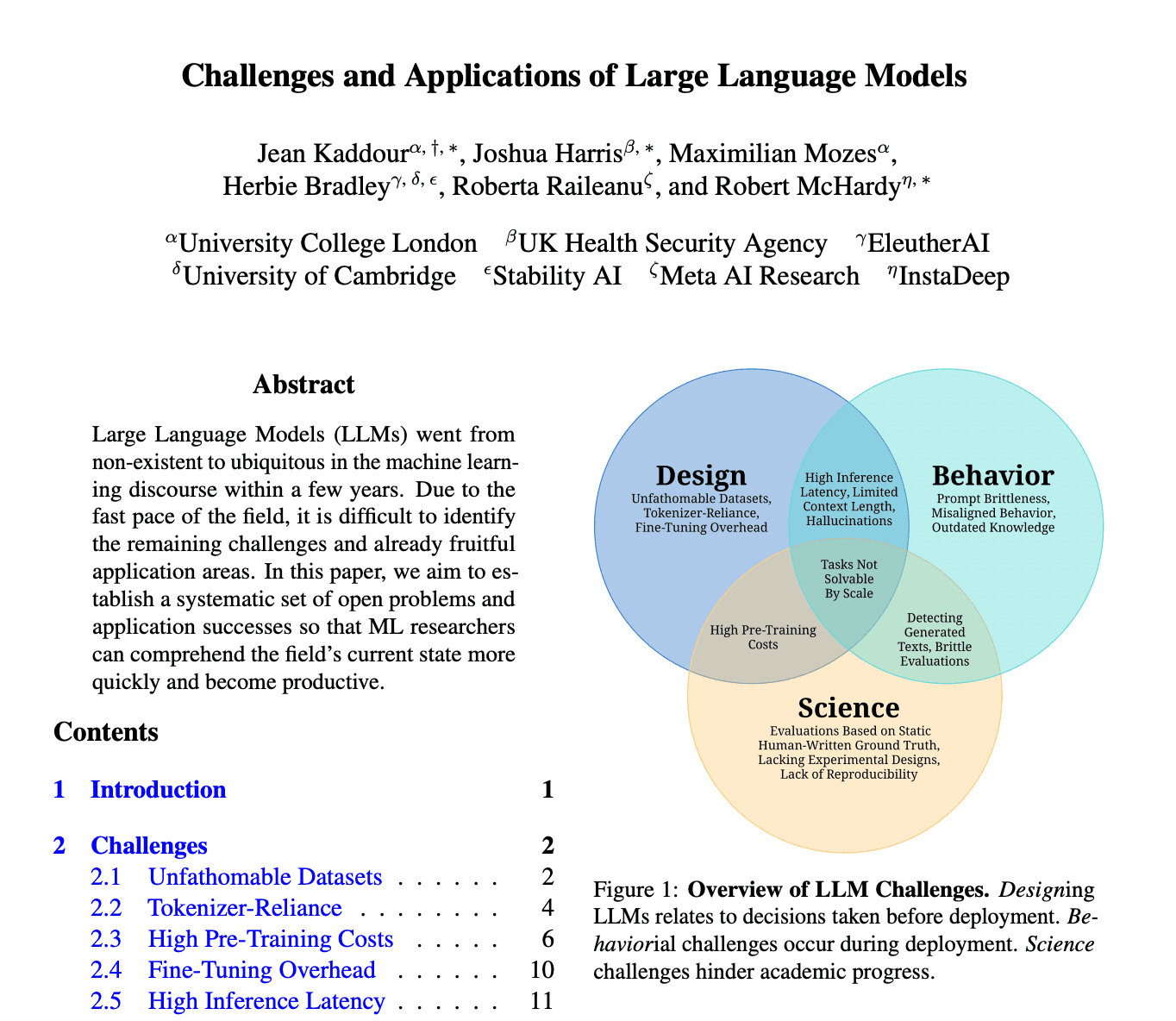
Large Language Models (LLMs) are widely used in machine learning for various applications. However, they come with challenges. The challenges can be grouped into three categories: Design, Behavior, and Science. Design challenges include dealing with massive and diverse datasets, the computational cost of tokenization, high pre-training costs, and limited context length. Behavior challenges involve prompt brittleness, misaligned behavior, and outdated knowledge. Science challenges include lack of reproducibility, evaluations based on outdated human-written ground truth, and tasks that cannot be solved by scaling alone. Despite these challenges, LLMs have been successfully applied in chatbots, computational biology, computer programming, creative work, and knowledge work. However, there is still room for improvement and innovation in LLMs by addressing these challenges and exploring new applications.
In the world of machine learning, Large Language Models (LLMs) have become commonplace. These models have shown success in a variety of applications, from chatbots to computational biology. However, despite their ubiquity, LLMs are not without their challenges. This tutorial will delve into the challenges and successful applications of LLMs, as outlined in a recent research paper.
The challenges associated with LLMs can be grouped into three broad categories: Design, Behavior, and Science.
Design challenges are inherent in the process of creating and implementing LLMs. These include:
Unfathomable datasets: The sheer size and diversity of data used for pre-training LLMs can be overwhelming. This includes datasets like GLaM, Infiniset, ROOTS, The Stack, LLaMA/Red-Pajama, and RefinedWeb.
Tokenizer-reliance: Tokenization is a crucial step in language model training, but it can be computationally expensive and introduce dependencies on pre-training data. Various tokenization algorithms, such as Byte-Pair Encoding (BPE), WordPiece, Unigram Tokenization, and SentencePiece, have been used in language models. Byte-level inputs have shown promising performance in multilingual tasks.
High pre-training costs: Pre-training LLMs requires significant computational resources and can be unsustainable in terms of cost and energy consumption. Compute-optimal training recipes aim to maximize training efficiency by determining the optimal size of the pre-training corpus and model given a compute budget.
Fine-tuning overhead and high inference latency: Fine-tuning LLMs on smaller task-specific datasets is highly effective for adapting them to downstream tasks. However, fine-tuning the entire LLMs requires large memory and storage requirements, making it infeasible for many practitioners. LLMs also have high inference latency due to low parallelizability and large memory footprints.
Limited context length: Limited context length is a challenge for language models, and various strategies such as efficient attention mechanisms, positional embedding schemes, and alternative architectures are being explored to address this issue.
Behavior challenges occur during the deployment of LLMs. These include:
Prompt brittleness: The wording and order of prompts can significantly impact the output of LLMs, leading to prompt brittleness. Variations in prompt syntax can result in significant changes in the model's output.
Misaligned behavior: Misaligned behavior refers to LLMs generating outputs that are not aligned with human values or intentions. Methods for addressing misaligned behavior include model evaluation, pre-training with human feedback, and instruction fine-tuning.
Outdated knowledge: Outdated knowledge in LLMs can be difficult to update without unintended side effects.
Science challenges hinder academic progress in the field of LLMs. These include:
Lack of reproducibility: Reproducibility is a challenge in LLM research, particularly in training runs and generations by closed-source API-served models. Training repeatability is affected by parallelism strategies and non-deterministic factors.
Evaluations based on static human-written ground truth: Evaluations based on static, human-written ground truth can become outdated and less useful over time. Dynamic evaluations without human involvement are being explored, including model-generated evaluation tasks and model-generated scores.
Tasks not solvable by scale: There are tasks that may not be solvable by scaling data and models alone. The phenomenon of inverse scaling, where task performance worsens as model scale and training loss performance increases, has been observed in autoregressive Transformer-based LLMs.
Despite these challenges, LLMs have found success in a variety of applications. These include:
Chatbots: Chatbots combine information retrieval, multi-turn interaction, and text generation tasks. Fine-tuning chatbots is challenging due to creating a broad training dataset of high-quality conversations.
Computational Biology: LLMs are used in computational biology for protein embeddings. Protein language models are often evaluated on academic datasets but their applicability to real-world projects like drug design is unclear.
Computer Programming: LLMs have been used for code generation tasks, such as generating Python functions from doc strings. Codex, Codex-S, and Polycoder are LLMs specifically designed for code generation, with Codex-S outperforming other models on Python code generation tasks.
Creative Work: LLMs have been applied to story and script generation, with the use of prompting and hierarchical generation. They have also been used for collaborative poetry generation, cross-lingual short story generation, news reel creation, creative writing assistance, and choice-based interactive fiction.
Knowledge Work: LLMs have been applied to domain-specific knowledge tasks in fields such as law and medicine. They have been evaluated on tasks in professional services, financial knowledge work, email management, chart understanding, news summarization, and data analysis.
In conclusion, while LLMs hold a lot of promise and have found success in a variety of applications, there are still many challenges to overcome. By understanding these challenges and the successful applications of LLMs, we can continue to improve these models and find new and innovative ways to use them.