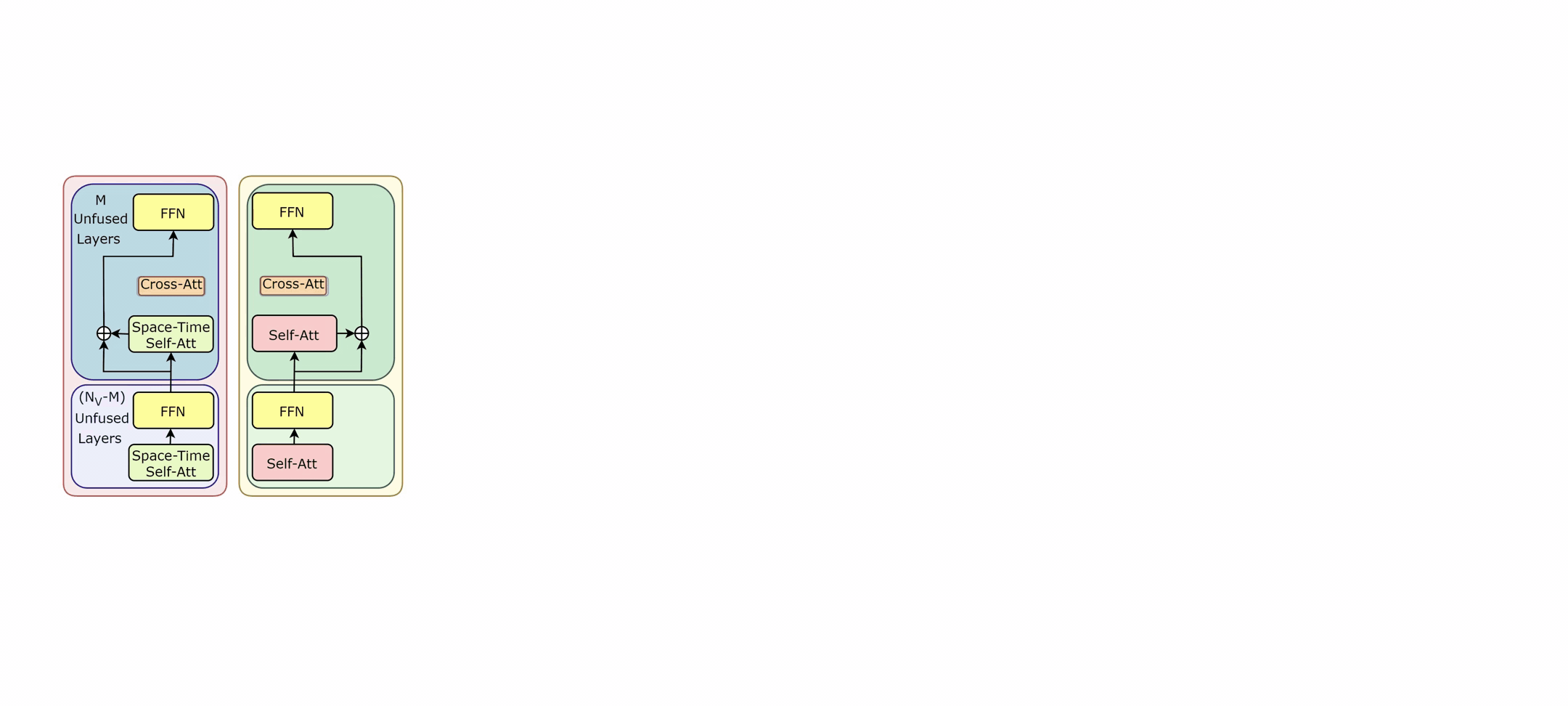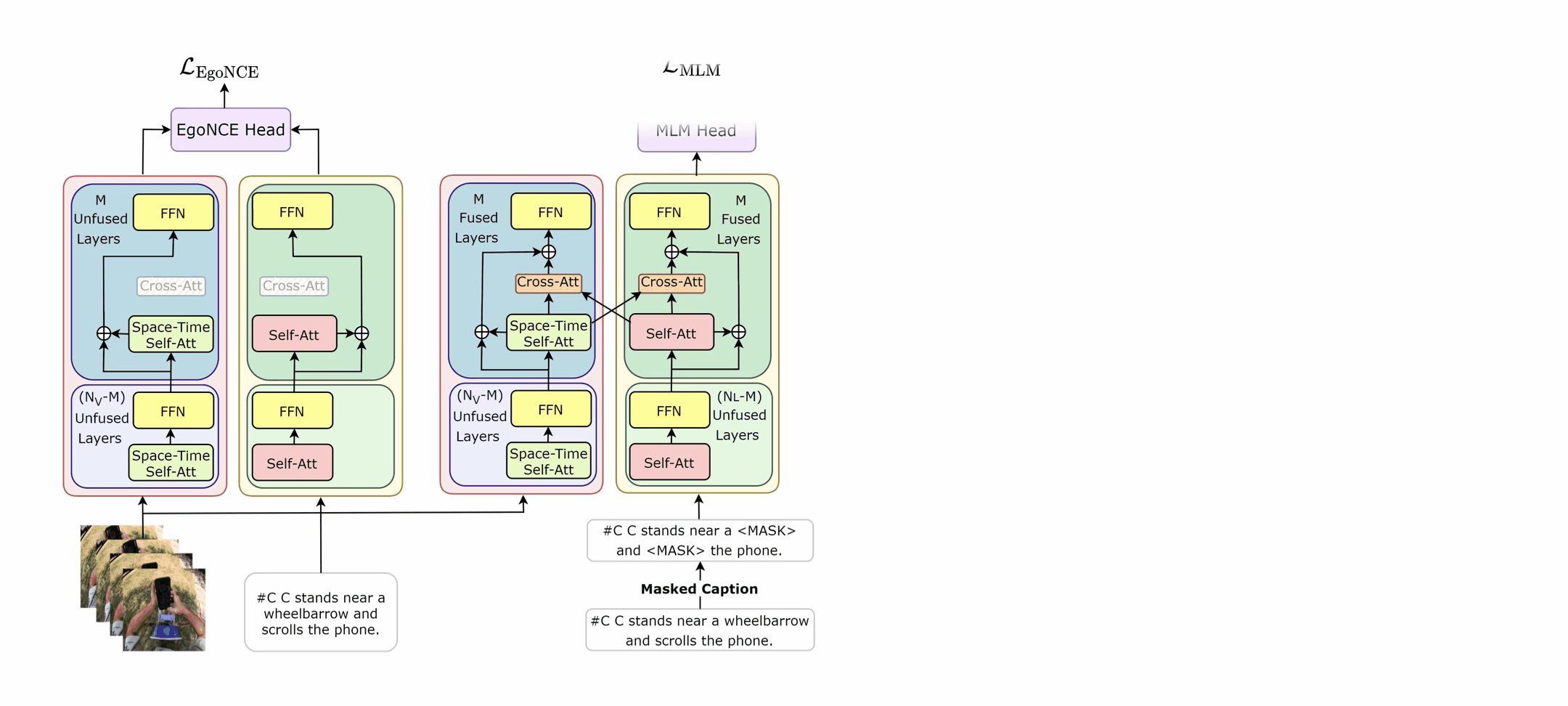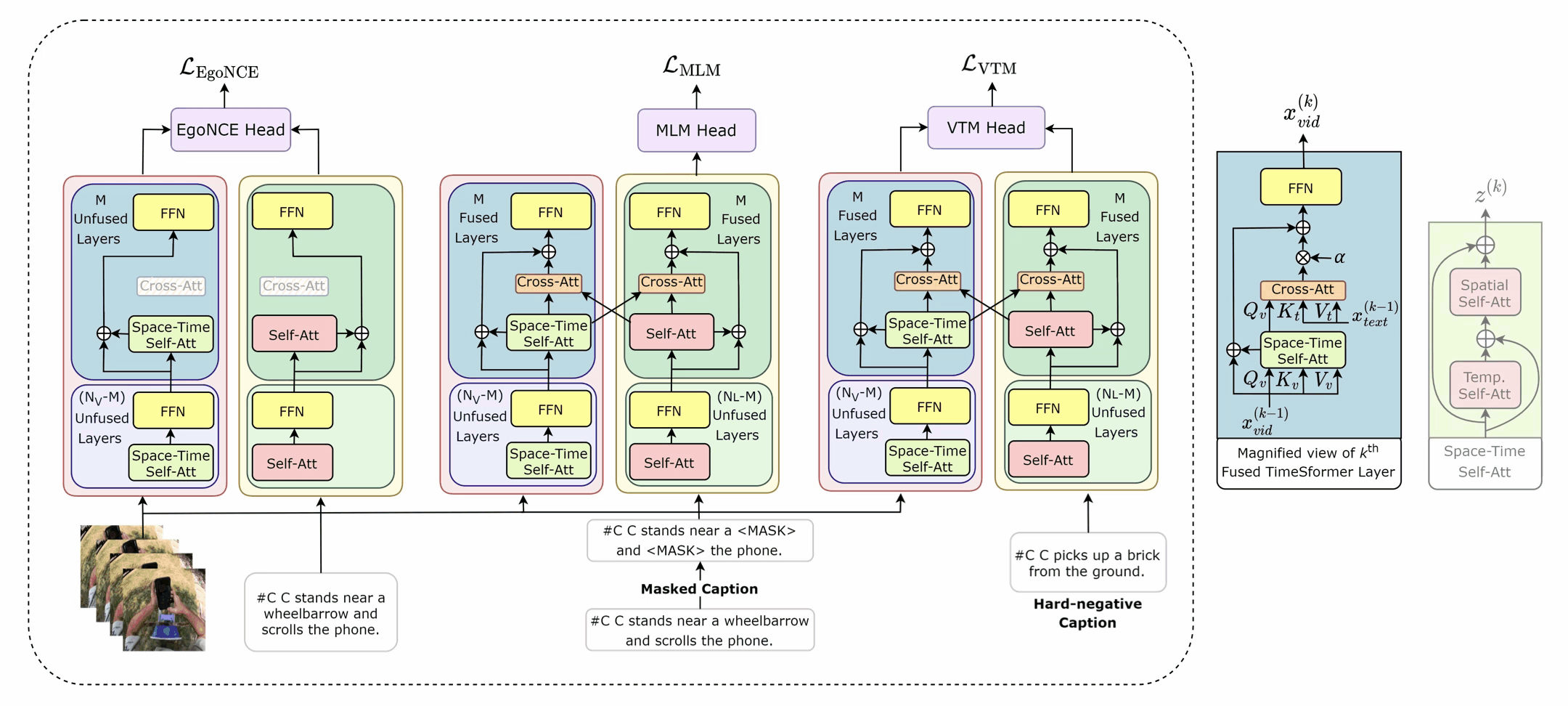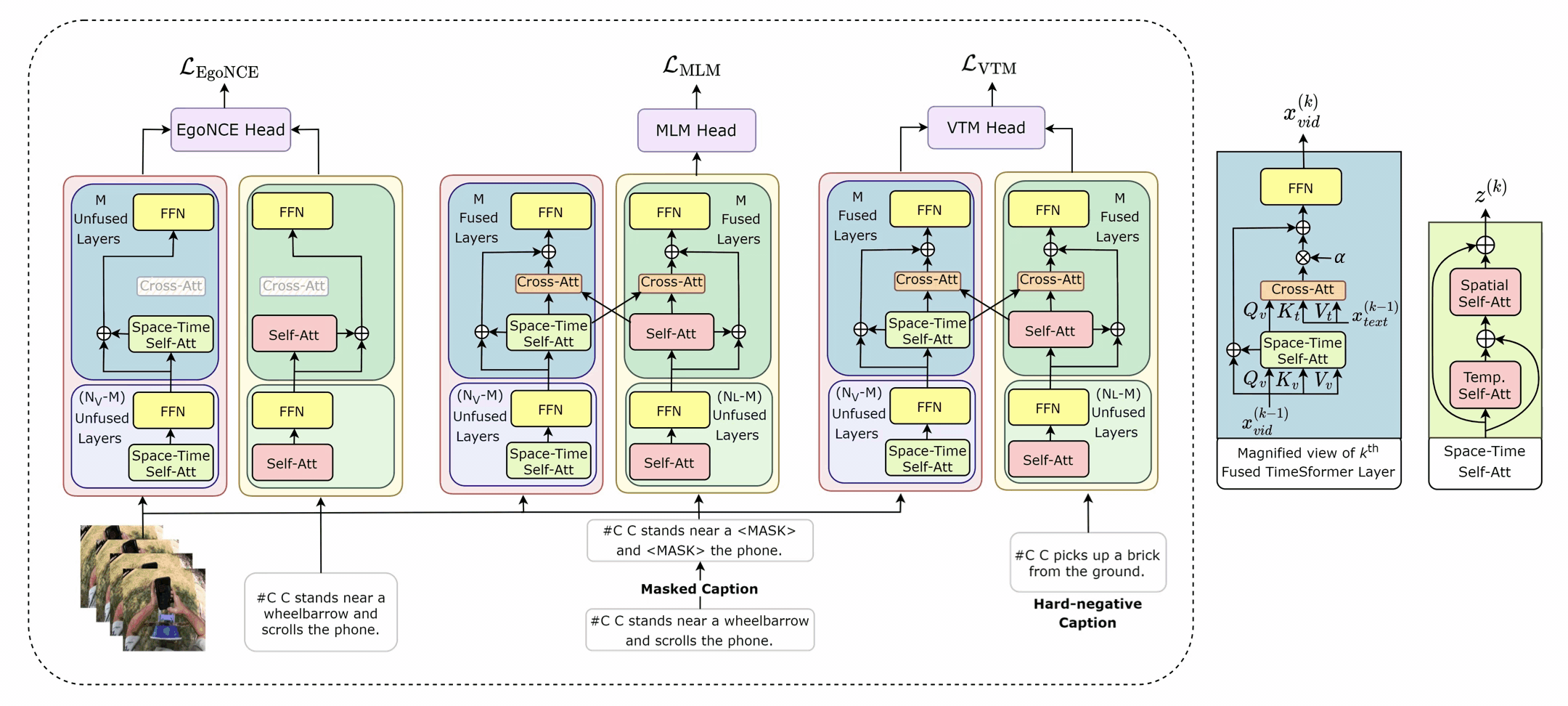Link to paper: https://arxiv.org/abs/2307.05463
Paper published on: 2023-07-11
Paper's authors: Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, Pengchuan Zhang
GPT3 API Cost: $0.07
GPT4 API Cost: $0.17
Total Cost To Write This: $0.24
Time Savings: 36:1
Introducing EgoVLPv2: A Leap Forward in Egocentric Video-Language Pre-training
Let's start with a simple analogy. If you think of a video as a book, its corresponding language or text is the summary or the blurb at the back of the book. The challenge lies in creating a model that can effectively understand and link the video (the book) and its corresponding language (the summary).
This is the crux of the research paper we're diving into today, which introduces EgoVLPv2, a second-generation model for egocentric video-language pre-training. This model is designed to understand and process first-person or egocentric videos, which are essentially videos taken from the perspective of the person performing the action, much like a GoPro footage.
Fusion in the Backbone: A Game-Changer for Video-Language Pre-training
In EgoVLPv2, the authors introduce a technique called fusion in the backbone. It's a method of incorporating cross-modal fusion directly into the video and language backbones of the model. This fusion strategy is more lightweight and compute-efficient than adding additional fusion-specific layers. It's like integrating the engine and the body of a car into a single unit, making the overall system lighter and more efficient.
Dual and Fusion Encoders: The Best of Both Worlds
One of the unique aspects of EgoVLPv2 is its ability to switch between dual and fusion encoders. This flexibility is achieved by turning the cross-attention modules on and off. It's akin to having a Swiss army knife that can adapt to various requirements by using different tools when needed.
Pre-training Objectives: The Building Blocks of EgoVLPv2
The EgoVLPv2 model is trained using three pre-training objectives: egocentric noise contrastive estimation (EgoNCE), masked language modeling (MLM), and video-text matching (VTM). These objectives guide the model in learning strong video-text representation during pre-training, which is then reused in different downstream tasks, thereby reducing fine-tuning costs.
The EgoVLPv2 model has been put to the test on a wide range of downstream tasks, including video-text retrieval, video grounding, and video question-answering. The model has achieved state-of-the-art performance on these tasks, surpassing existing baselines. It's like having a new record holder in a series of Olympic events.
The Power of Large-Scale Open-World Video-Text Datasets
The success of EgoVLPv2 is attributed in part to the availability of large-scale open-world video-text datasets such as ActivityNet, WebVid-2M, and HowTo100M. These datasets provide a rich and diverse range of videos and corresponding text, which serve as valuable training material for the model.
The Future: Building and Learning with EgoVLPv2
With the capabilities of EgoVLPv2, we can imagine a future where advanced video understanding tasks are performed with greater efficiency and accuracy. For instance, a model trained using EgoVLPv2 could potentially be used in wearable cameras to provide real-time assistance to users, or in autonomous vehicles to better understand and navigate the environment.
The introduction of the fusion in the backbone strategy also opens up new possibilities for the development of more lightweight and compute-efficient models. This could lead to faster processing times and lower computational costs, making advanced video understanding models more accessible and practical for a wide range of applications.