Link to paper: https://arxiv.org/abs/2307.10802
Paper published on: 2023-07-20
Paper's authors: Yiyuan Zhang, Kaixiong Gong, Kaipeng Zhang, Hongsheng Li, Yu Qiao, Wanli Ouyang, Xiangyu Yue
GPT3 API Cost: $0.05
GPT4 API Cost: $0.13
Total Cost To Write This: $0.18
Time Savings: 35:1
The ELI5 TLDR:
The Meta-Transformer is a new framework that can process and relate information from different types of data. It can handle 12 different types of data, like text, images, and audio, all at once. The framework has three main parts: a data tokenizer, an encoder, and task-specific heads. The tokenizer turns the data into tokens, the encoder extracts important features from the tokens, and the heads make predictions based on what the model has learned. The Meta-Transformer has been tested on different tasks and has shown good results in tasks like sentiment analysis, image classification, and audio recognition. However, it has some limitations and future research can explore how it can be used for generative tasks. Overall, the Meta-Transformer has the potential to improve how we analyze and understand different types of data.
The Deeper Dive:
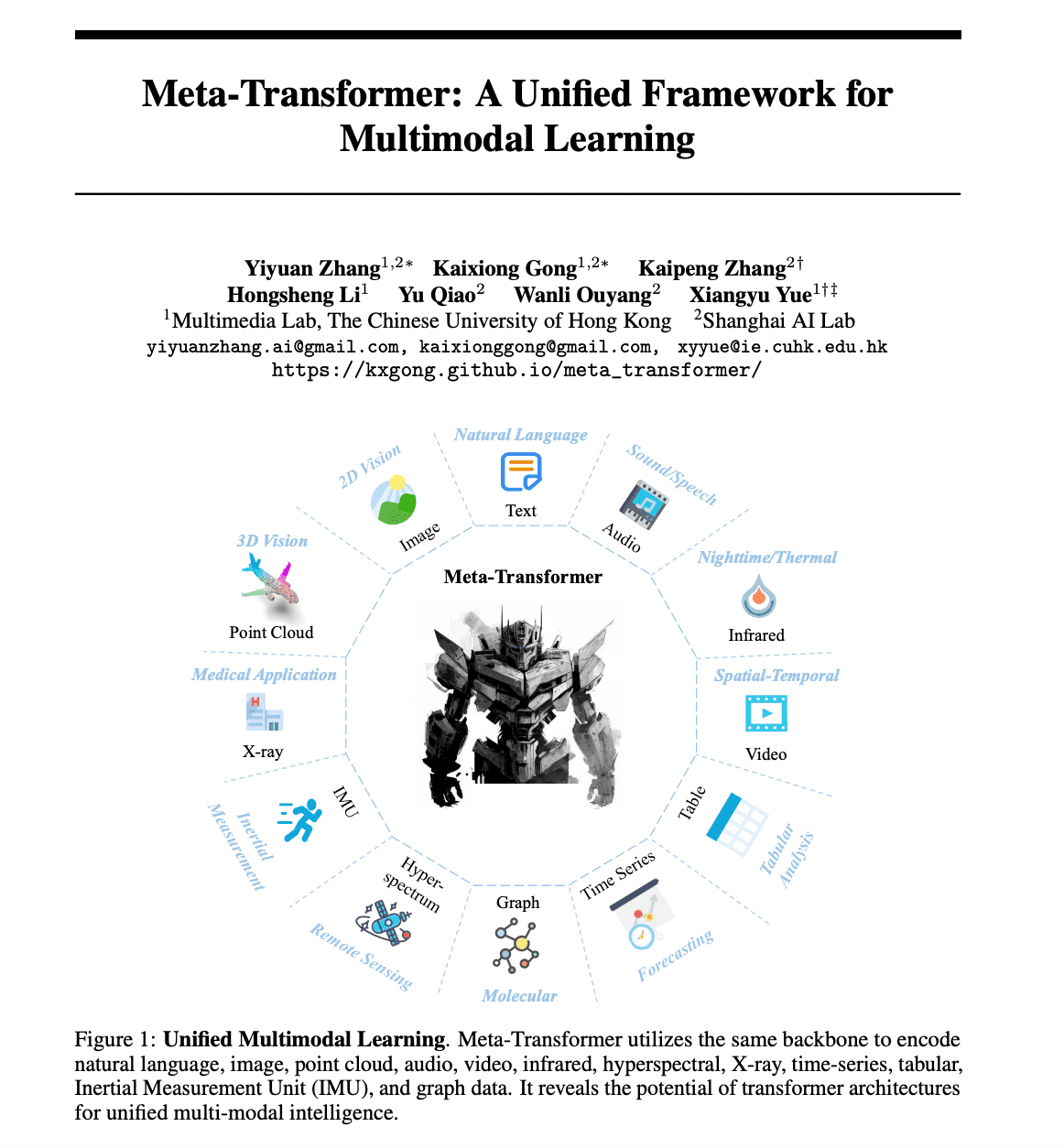
The recent research paper presents an innovative framework known as the Meta-Transformer. This model is designed to process and relate information from multiple modalities, a task known as multimodal learning. The novelty lies in its ability to perform unified learning across 12 different modalities with unpaired data, something that no other framework has achieved before.
The Meta-Transformer consists of three main components: a unified data tokenizer, a modality-shared encoder, and task-specific heads for downstream tasks. It uses the same backbone to encode data from various modalities such as natural language, image, point cloud, audio, video, infrared, hyperspectral, X-ray, time-series, tabular, Inertial Measurement Unit (IMU), and graph data.
Unified Data Tokenizer
The unified data tokenizer is the first component of the Meta-Transformer. It transforms raw input data from different modalities into token embeddings within a shared manifold space. This shared space is crucial as it allows the model to process and relate information from different modalities.
Modality-Shared Encoder
The modality-shared encoder is the second component of the Meta-Transformer. It uses a frozen pre-trained backbone network, specifically the Vision Transformer (ViT), to extract high-level semantic features from the token embeddings. The encoder also incorporates position embeddings to encode the token embeddings.
Task-Specific Heads
The task-specific heads are the final component of the Meta-Transformer. They are designed to perform predictions based on the learned representations. These heads are task-specific, meaning they are designed and trained for specific downstream tasks such as object detection, image classification, or sentiment analysis.
Experimental Results and Applications
The Meta-Transformer was tested across a range of tasks and modalities, demonstrating its potential. For example, it showed competitive performance in various natural language understanding tasks such as sentiment analysis, paraphrase detection, duplication detection, inference, and answering tasks.
In image understanding tasks, the Meta-Transformer outperformed other methods in zero-shot image classification and achieved high accuracy in object detection and semantic segmentation. It also demonstrated potential in handling challenges associated with infrared images, hyperspectral image recognition, and 3D point cloud understanding.
In audio recognition, the Meta-Transformer achieved high accuracy with fewer trainable parameters compared to existing methods. Similarly, in video recognition, it demonstrated competitive performance in accuracy while requiring fewer trainable parameters compared to other methods.
Limitations and Future Work
Despite its promising results, the Meta-Transformer does have some limitations. It lacks temporal and structural awareness, which may affect its performance in tasks where these factors are important. The complexity of the Meta-Transformer also makes it difficult to scale up.
Future research can explore the effectiveness of Meta-Transformer in generative tasks and develop modality-invariant generative models. This could potentially open up new possibilities for cross-modal generation, such as generating an image from a textual description or vice versa.
Conclusion
The Meta-Transformer provides a promising new direction in developing a modality-agnostic framework capable of unifying all modalities. Its unified learning framework enhances the potential for more accurate and comprehensive analysis in various fields. From natural language understanding to image recognition, and from audio recognition to video understanding, the Meta-Transformer has shown its potential to revolutionize multimodal learning.