Link to paper: https://arxiv.org/abs/2307.03869
Paper published on: 2023-07-08
Paper's authors: Aditya Sanghi, Pradeep Kumar Jayaraman, Arianna Rampini, Joseph Lambourne, Hooman Shayani, Evan Atherton, Saeid Asgari Taghanaki
GPT3 API Cost: $0.04
GPT4 API Cost: $0.14
Total Cost To Write This: $0.17
Time Savings: 17:1
Introduction and Summary
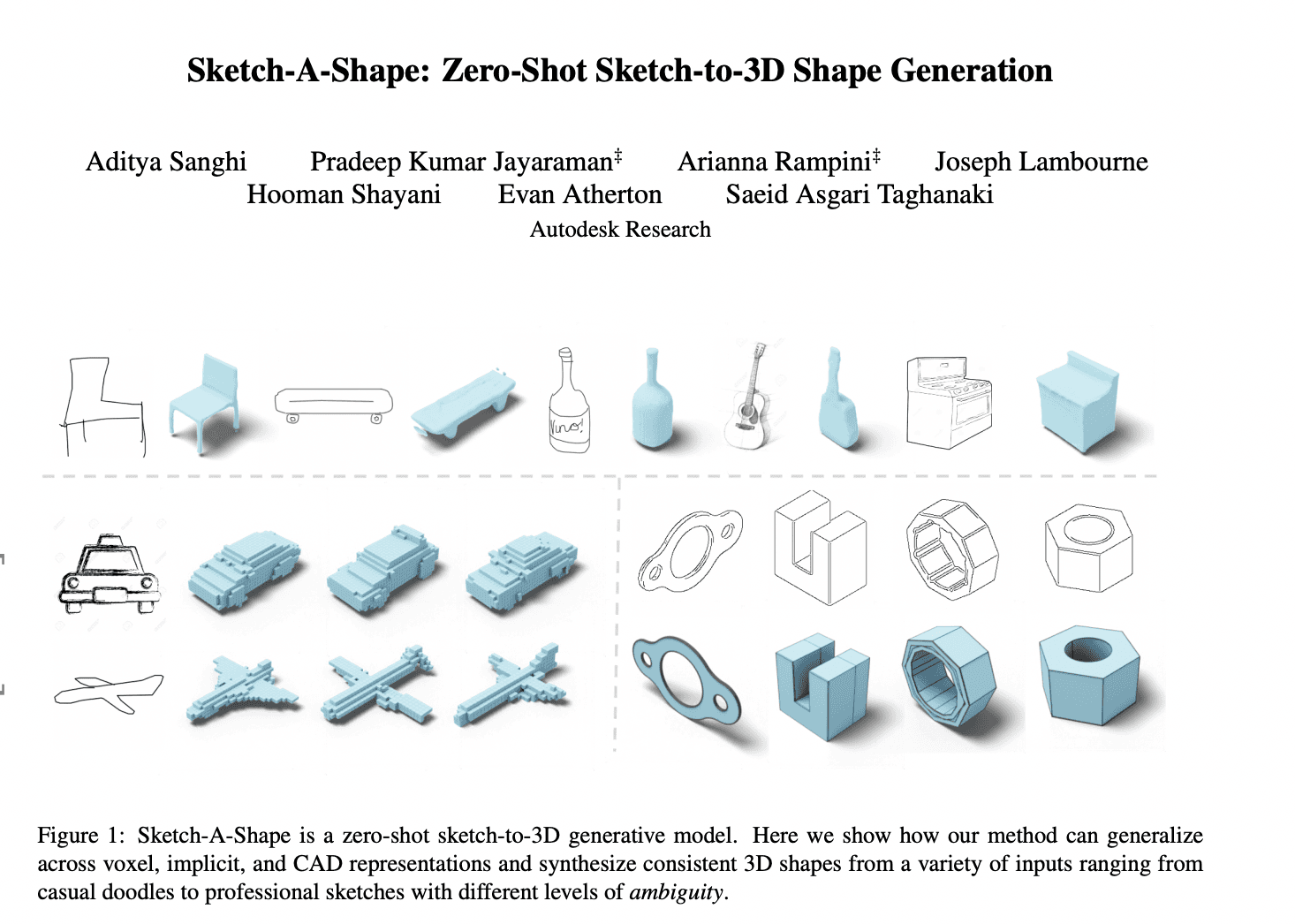
Let's start with an exciting development in the field of AI research: the creation of Sketch-A-Shape. This is a zero-shot approach for generating 3D shapes from sketches by leveraging large-scale pre-trained models. This method does not require paired sketch-3D datasets, which is a significant departure from many previous approaches.
Imagine an artist sketches a concept for a new product, and instead of spending hours or days creating a 3D model of that sketch, an AI model generates it instantly. This is the exciting potential of Sketch-A-Shape.
The Methodology
The approach involves two training stages. The first stage is training a discrete auto-encoder to capture the shape distribution. The second stage involves training a masked transformer to generate shape indices conditioned on a sketch.
The discrete auto-encoder, in this case, is a type of neural network that learns to compress the input data into a lower-dimensional representation and then reconstructs the data from this representation. The masked transformer, on the other hand, is a type of transformer model that predicts the next item in a sequence.
One of the key points of this method is that it can generate multiple 3D shapes per input sketch, regardless of the level of abstraction in the sketches. This means it works equally well on everything from simple doodles to professional sketches.
The Novelty of Sketch-A-Shape
The novelty of this approach lies in not training on paired shape-sketch data. Instead, it relies on the robustness of local semantic features from a pre-trained image encoder. This is a significant departure from many previous methods that require paired data for training.
Another interesting aspect is that this method can be applied to different 3D representations, such as voxels, CAD, and implicit representations. This versatility makes it highly adaptable and potentially useful in a variety of applications.
The Training Objective and Cross-Attention Mechanism
The method uses a cross-attention mechanism and a training objective to unmask masked shape indices. The cross-attention mechanism allows the model to focus on different parts of the input sketch when generating the 3D shape. The training objective, on the other hand, is to correctly predict the masked shape indices, which are hidden parts of the shape that the model needs to guess based on the rest of the shape and the input sketch.
Importance of Pre-Trained Model and Deeper Layers
The choice of pre-trained model is important, and larger models trained on diverse data produce better results. Specifically, deeper layers in the pre-trained models generate more semantic features and yield better results. This is because deeper layers in a neural network typically capture more complex and high-level features.
The method uses a mapping network to convert the grid structure of the features into a sequence. This is important for the transformer model, which works with sequences of data.
In addition, the method utilizes conditional information from the sketch to generate 3D shapes during the inference phase. This means that the generated 3D shape is not just based on the learned shape distribution, but also takes into account the specific details in the input sketch.
Evaluation and Results
The method is evaluated using different sketch datasets and achieves high classification accuracy. Human perceptual evaluation shows that the generated 3D models preserve important geometric and stylistic details from the sketches.
Interestingly, the method outperforms a supervised approach called Sketch2Model in terms of generation capabilities. This means that even without explicit paired sketch-3D shape data for training, the method can still generate more accurate and diverse 3D shapes.
The Role of Local Grid Features and Size of Pre-Trained Models
The researchers investigate the importance of utilizing local grid features of pre-trained models for generating 3D shapes from sketches. They find that leveraging local grid features yields better performance.
They also explore the role of the size of pre-trained models and find that increasing the size of the same class of pre-trained model results in better zero-shot performance. This is consistent with the general trend in deep learning that larger models tend to perform better, given enough data and computational resources.
Future Work and Potential Applications
The researchers conclude by demonstrating the robustness of their method and discuss future work involving training on larger and diverse 3D shape datasets and testing on different styles of sketches and levels of details.
In terms of potential applications, this research could be used to build new tools for artists, designers, and engineers, among others. For instance, it could be used to create a tool that instantly turns sketches into 3D models, which could significantly speed up the design process in various fields. It could also be used in education to help students visualize 3D shapes and structures.